
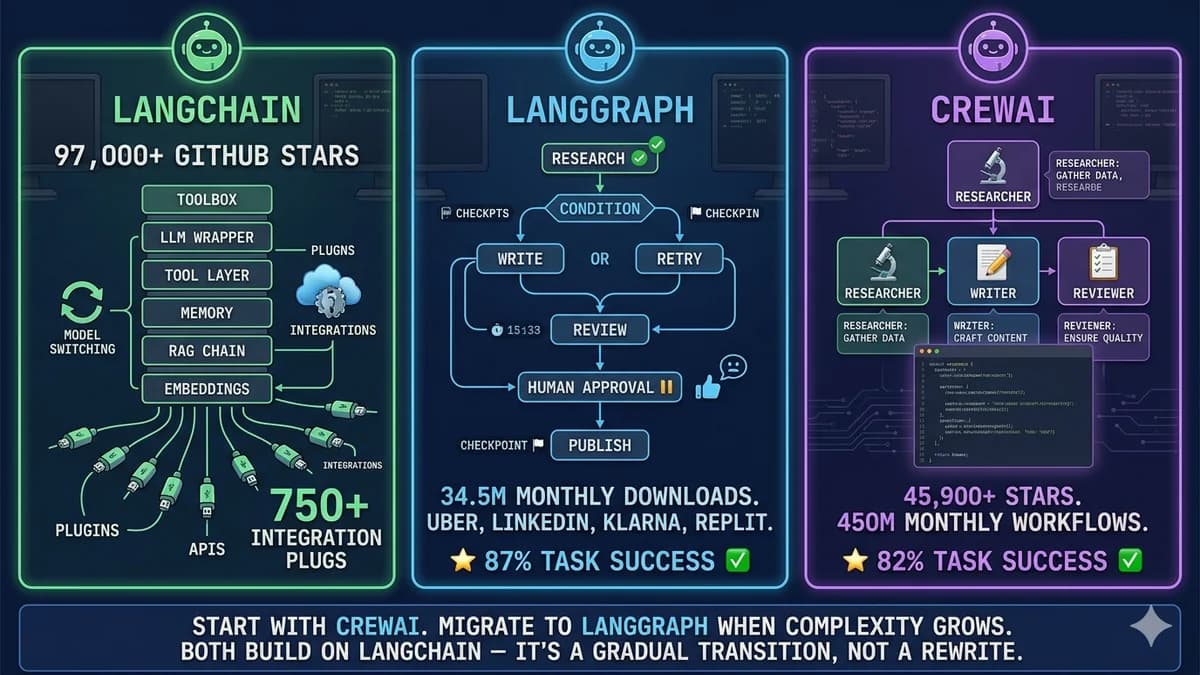
The Distinction That Predicts the Answer
As of March 2026, the AI agent framework landscape has consolidated around two primary players: CrewAI and LangGraph (with its parent ecosystem, LangChain). Every comparison guide you will find covers features. This one starts somewhere more useful: the definitional distinction that predicts which framework fits your problem before you look at a single feature.
CrewAI is a role-orchestration framework. It optimises for expressing who does the work. You define agents as team members with roles, goals, and backstories — Researcher, Writer, Reviewer — and assemble them into a "crew" that collaborates through natural language delegation. If your problem maps to a team analogy, CrewAI is the right mental model and you will be productive in hours.
LangGraph is a state-machine framework. It optimises for expressing what happens to data between steps. You define agents as nodes in a directed graph, edges as control flow transitions, and a typed state object that flows between nodes. Every transition is explicit. Every state change is traceable. If your problem requires conditional branching, crash recovery, human approval gates, or audit trails, LangGraph gives you the explicit control to implement them correctly.
LangChain is the ecosystem both build on. It provides the tool integrations, LLM wrappers, RAG components, and embedding infrastructure that CrewAI agents and LangGraph nodes both consume. Most production agent systems use LangChain components regardless of which orchestration framework they use for agent coordination.
Start with CrewAI. You get a working multi-agent system in hours, ~20 lines of code, and role assignments that are immediately legible to non-technical stakeholders. Migrate the parts that need more control to LangGraph as complexity grows. This is not a failure to commit — it is the path most production teams actually take. CrewAI is built on LangChain, which means the migration from CrewAI to hybrid CrewAI/LangGraph is incremental, not a rewrite. The exception: if you already know your use case requires conditional branching, crash recovery, or human-in-the-loop approvals, skip CrewAI and start with LangGraph. The week of learning pays back immediately.
Framework Snapshot — April/May 2026 Data
The three frameworks occupy distinct layers of the agent stack — ecosystem, runtime, and role orchestration. The numbers below capture each project's scale and production posture in the current cycle, before the feature-by-feature comparison that follows.
LangChain
LangGraph
CrewAI
Feature Comparison — The Dimensions That Determine Production Fit
The feature matrix below covers the 13 dimensions that most consistently determine production fit across the three frameworks. Green cells mark a clear strength, amber marks a workable middle, red marks a known weakness — read it as a shape, not a scorecard.
| Dimension | LangChain | LangGraph | CrewAI |
|---|---|---|---|
| Learning Curve | Low — intuitive abstractions | Medium-High — graph thinking required | Low — role/task metaphor |
| Multi-Agent Support | Basic — single-agent optimised | Strong — native graph patterns | Excellent — core purpose |
| State Management | Basic memory system | First-class typed state + persistence | Managed internally |
| Conditional Branching | Awkward — nested chains | Native conditional edges, cycles | Limited — sequential/hierarchical |
| Human-in-the-Loop | Manual implementation | First-class breakpoints + persistence | Basic support |
| Crash Recovery | Not built-in | Checkpointing — resume from last state | Not built-in |
| Debugging | Moderate — abstractions hide issues | Excellent — explicit state at every step | Limited — internal state less accessible |
| Production Observability | LangSmith (trace, cost, eval) | LangSmith (full integration) | Enterprise plan — less mature |
| Token Cost Efficiency | Standard LLM call overhead | Routing logic as pure Python — zero LLM calls | Every delegation = LLM call |
| Setup Speed | Fast for single agent/RAG | ~60+ lines for multi-agent | ~20 lines for multi-agent |
| MCP/A2A Support | Via LangChain tooling | Via LangChain tooling | Native (2026) |
| Tool Integrations | 750+ | 750+ (via LangChain) | Via LangChain or custom |
| Auditability | Moderate | Excellent — full state history | Limited |
Benchmark Data — Performance Numbers From Production Testing
The benchmark data below reflects community and production testing reported across multiple engineering teams in April/May 2026. These numbers reflect real workloads — not vendor benchmarks.
The benchmark patterns reveal two specific strengths: LangChain's optimised RAG chains win on single-agent document retrieval tasks — 1.2s versus CrewAI's 1.8s. CrewAI's multi-agent coordination produces efficiency gains when multiple agents collaborate — 45s versus 68s for a 5-step research workflow. LangGraph's 87% task success rate reflects production-hardened state management across the workflow types that break other frameworks (conditional branching, retry logic, complex state passing). The 5-point gap versus CrewAI's 82% reflects LangGraph's more explicit error handling, not raw LLM capability.
The API cost dimension is the benchmark most comparison posts skip: in a LangGraph workflow, routing decisions can be pure Python functions with zero LLM calls. In CrewAI, every delegation between agents triggers an LLM call. Over a multi-step pipeline with many agents, this difference compounds into real API bill differences — $200-$2,000+ per engineer per month in agentic workloads means token efficiency matters at scale.
The 5 Production Dimensions — Where the Frameworks Diverge Hardest
Feature matrices flatten the tradeoffs. The five dimensions below are where the three frameworks diverge most sharply in real production systems — token cost, crash recovery, human-in-the-loop, debugging, and setup speed. Each dimension is the question, followed by how each framework actually behaves in production.
Token Cost at Scale — Does every agent coordination cost money?
Standard LLM call overhead for each agent action. Efficient for single agents. Overhead grows with chain complexity.
Routing decisions as pure Python functions — zero LLM tokens. You control exactly which nodes invoke the model. Lowest token cost for complex multi-step workflows.
Every delegation between agents triggers an LLM call — including coordination overhead. Confirmations and clarifications consume tokens without advancing the task. Cost compounds in large crews.
Crash Recovery — What happens when an agent fails at step 7 of 12?
No built-in checkpointing. Failures restart from step 1. Acceptable for short workflows; increasingly painful as complexity grows.
Checkpointing at every state transition. Agent resumes from last successful checkpoint after any failure. Non-negotiable for long-running workflows or production systems processing real customer data.
No built-in checkpointing. Long-running crew workflows have no recovery mechanism — a failure restarts from the beginning. Acceptable for short tasks; increasingly risky as workflow duration grows.
Human-in-the-Loop — Can a human approve, modify, or reject at defined points?
Requires custom implementation. Not a first-class concept in the framework — you build your own interrupt and approval mechanism.
First-class support with breakpoints and persistence. Define exactly which nodes pause for human review. State is preserved during the pause. Required for any regulated context — compliance, financial decisions, healthcare.
Basic human input support. Works for simple approval gates but lacks the state persistence and precise breakpoint control that regulated contexts require.
Debugging — When agent step 7 makes a bad decision, can you trace what happened?
Moderate debugging. Abstractions can obscure what happened. LangSmith provides trace visibility. Works for simpler workflows; gets harder with complex chains.
Explicit typed state at every transition makes every decision reconstructable. LangSmith traces, cost tracking, and prompt versioning out of the box. Best debugging experience in the comparison by a significant margin.
Internal state is less accessible than LangGraph's explicit state. CrewAI Enterprise adds management views, but the natural language delegation model makes tracing agent decisions harder than LangGraph's structured state.
Setup Speed — How long to a working multi-agent prototype?
Fast for single agents and RAG. Multi-agent coordination requires more custom work — LangGraph is the recommended path for complex multi-agent LangChain systems.
~60+ lines of code for a multi-agent workflow. Graph paradigm requires about a week to internalise for developers new to it. Pays back immediately once learned — especially if your use case needs conditional branching.
~20 lines of code for a working multi-agent system. Working prototype in 2-4 hours. Role-based mental model is immediately legible to both developers and non-technical stakeholders. The fastest path from zero to running agents.
Code Contrast — What the Same Task Looks Like in Each Framework
The code contrast below shows a three-agent research workflow (Researcher → Writer → Reviewer) in both CrewAI and LangGraph. Same task, different philosophy.
CrewAI — Role-Based Team (~20 lines)
from crewai import Agent, Task, Crew
# Define agents with roles, goals, backstories
researcher = Agent(
role="Researcher",
goal="Find accurate, up-to-date information on the topic",
backstory="Expert research analyst with deep domain knowledge",
tools=[search_tool]
)
writer = Agent(role="Writer", goal="Write clear, compelling content")
reviewer = Agent(role="Reviewer", goal="Ensure quality and accuracy")
# Define tasks and assemble the crew
crew = Crew(
agents=[researcher, writer, reviewer],
tasks=[research_task, write_task, review_task],
process="sequential"
)
result = crew.kickoff() # Crew runs — natural language delegationLangGraph — State Machine (~60+ lines)
from langgraph.graph import StateGraph, END
from typing import TypedDict, Literal
# Define explicit typed state
class ResearchState(TypedDict):
topic: str
research: str
draft: str
review_result: Literal["approved", "needs_revision"]
revision_count: int
# Define nodes (each is a function operating on state)
def research_node(state: ResearchState) -> ResearchState:
state["research"] = research_agent.run(state["topic"])
return state
def should_revise(state) -> str: # Conditional edge — zero LLM tokens
if state["review_result"] == "needs_revision" and state["revision_count"] < 3:
return "write" # loop back
return "end"
# Build the graph — explicit control over every transition
graph = StateGraph(ResearchState)
graph.add_node("research", research_node)
graph.add_node("write", write_node)
graph.add_node("review", review_node)
graph.add_conditional_edges("review", should_revise)
graph.add_edge("research", "write")
graph.add_edge("write", "review")
# With checkpointing — crash recovery built in
app = graph.compile(checkpointer=memory_checkpointer)The code contrast makes the philosophy concrete. CrewAI reads like a team briefing — you are assigning roles and missions. LangGraph reads like an engineering spec — you are defining state schemas, transition functions, and conditional routing. Both accomplish the same three-agent task. The LangGraph version adds conditional revision loops and crash recovery that the CrewAI version cannot express in its sequential model. At five or six agents, the individually testable LangGraph nodes become easier to audit than an equivalent YAML-configured CrewAI crew.
Building an AI agent system and unsure which framework fits your architecture?
Automely's engineers have built production agent systems using LangChain, LangGraph, and CrewAI. We scope the right stack for your use case. Free 45-minute call.
Decision Matrix — Match Your Use Case to the Framework
The decision matrix below maps concrete use case patterns to the framework that most consistently fits them in production — including the hybrid CrewAI → LangGraph path that most production teams converge on as their systems grow.
You need a single agent that calls tools and returns a result. RAG chatbots, simple automation tasks, document Q&A, model-switching pipelines, and applications that need breadth of tool integrations (750+ connectors). LangChain is also the ecosystem layer for both LangGraph and CrewAI — use it regardless of which orchestration framework you choose for the LLM wrappers, embeddings, and tool integrations.
Your workflow maps to clear agent roles (Researcher, Writer, Reviewer) and sequential or hierarchical task flow without complex branching. You need a working multi-agent prototype this week. You are building content pipelines, research automation, report generation, or business process workflows. Your team is new to agent frameworks and needs the gentlest learning curve. Your agents run independently without heavy inter-agent state coordination. Agents API costs are manageable at your target scale.
Your workflow has conditional branching, loops, parallel execution with merging, or complex retry strategies. You need crash recovery — LangGraph's checkpointing lets agents resume after failures without restarting from step 1. Human approvals are required at defined workflow points (compliance, financial decisions, medical contexts). You need audit trails — regulated contexts require reconstructable decision logs. You are already invested in LangChain's ecosystem. You are building compliance systems, financial pipelines, customer-facing SaaS features, or any context where reliability is non-negotiable.
Your production system has more than 5-6 agents. At this scale, LangGraph's individually testable nodes become significantly easier to audit, debug, and maintain than an equivalent YAML-configured CrewAI crew. The maintainability crossover point is sharp — teams that prototype in CrewAI and migrate production-critical parts to LangGraph report this transition as one of the best architecture decisions they made.
You are building a new multi-agent system and are not yet sure how complex it will get. Start in CrewAI. Build fast, validate the core use case, demonstrate value. Migrate the parts that hit complexity walls — conditional branching, state persistence, human approval gates — to LangGraph incrementally. CrewAI is built on LangChain, so you can use LangChain tools inside your CrewAI agents; migrating to hybrid CrewAI/LangGraph is not a rewrite. Plan this migration path from day one if you expect enterprise-scale requirements eventually.
The Migration Path — How Production Teams Actually Transition
The most common real-world pattern: teams prototype in CrewAI, ship a working multi-agent system, then migrate production-critical parts to LangGraph as reliability and auditability requirements emerge. This is not a failed architecture choice — it is the engineering path that most production teams take, and both frameworks are designed to support it.
The migration works incrementally because CrewAI is built on LangChain. You can continue using your LangChain tool integrations, LLM wrappers, and embedding infrastructure. The migration is scoped to the agent orchestration layer — replacing the CrewAI crew coordination with LangGraph graph-based state management for the workflows that need it, while keeping CrewAI for the role-based workflows that still fit the sequential model.
Practical migration trigger points to watch for:
- Your crew has more than 5-6 agents and you are struggling to trace which agent made which decision at which point — LangGraph's explicit state makes this tractable.
- A long-running workflow fails mid-execution and you are restarting from step 1 repeatedly — LangGraph checkpointing is the specific fix.
- A regulated use case requires human approval at a specific workflow point — LangGraph's first-class interrupt support handles this; CrewAI's basic support may not satisfy compliance requirements.
- Token costs are growing faster than workflow complexity — replacing CrewAI's natural-language delegation with LangGraph's Python routing logic eliminates the inter-agent LLM call overhead.
- You need to deploy LangSmith for production monitoring — this is native to LangGraph and requires more work to integrate with CrewAI's internal state model.
MCP (Model Context Protocol) is Anthropic's open standard for connecting AI agents to tools — the "USB-C of agent tool integration." All three frameworks are adopting it in 2026. CrewAI added native MCP and A2A support in early 2026. LangGraph adopts MCP through LangChain tooling. A2A (Google's Agent-to-Agent protocol) enables agents from different frameworks to collaborate in the same multi-agent system. The practical implication: MCP adoption means your tool integrations are increasingly portable across framework choices. Framework selection is becoming a state management and orchestration decision more than a tool integration decision. Learn MCP — it is becoming infrastructure.
Building AI Agent Systems with Automely
Automely's AI agent development service builds production agent systems using LangChain, LangGraph, and CrewAI — selecting and combining frameworks based on the specific use case, team context, and production requirements of each project.
Our framework selection approach follows the same decision matrix in this guide. We use LangChain for RAG pipelines, tool integrations, and single-agent applications. We use LangGraph for production-grade stateful agents requiring conditional branching, crash recovery, and human-in-the-loop workflows — including the regulated contexts (banking, healthcare, HR) covered in our other deployment guides. We use CrewAI for rapid multi-agent prototype development and content/research pipeline automation where the role-based model maps naturally to the workflow.
Most of our production agent systems combine frameworks — CrewAI for the role-orchestration layer with LangGraph for the stateful core of the most reliability-critical workflows. This hybrid architecture is the production-tested approach that most engineering teams converge on after learning the tradeoffs the hard way. We have built it enough times to scope the integration correctly from day one.
Automely builds production AI agents — LangChain integrations, LangGraph multi-agent orchestrations, CrewAI workflows, custom agent frameworks, RAG-enabled agents, and tool-calling systems. AI agent projects start from $15,000. Book a free 45-minute consultation at cal.com/Automely.ai/45min.
Browse our case studies, read client testimonials, and explore our full AI services portfolio including generative AI development and AI integration services. For the broader framework selection lens, see our AI framework selection guide for 2026. For the end-to-end build playbook, see our AI agent build guide. For the production hardening that LangGraph specifically targets, see our AI agent production deployment guide.
Need the framework selected, the architecture scoped, and the agent system built — without spending weeks learning the tradeoffs the hard way?
Book a free 45-minute AI agent build consultation. We scope the framework stack, design the state architecture, and estimate the build. Before any development commitment.